CI Tests: Why We Moved to AWS Spot Instances
We failed with Kubernetes, and then switched to Lambdas.


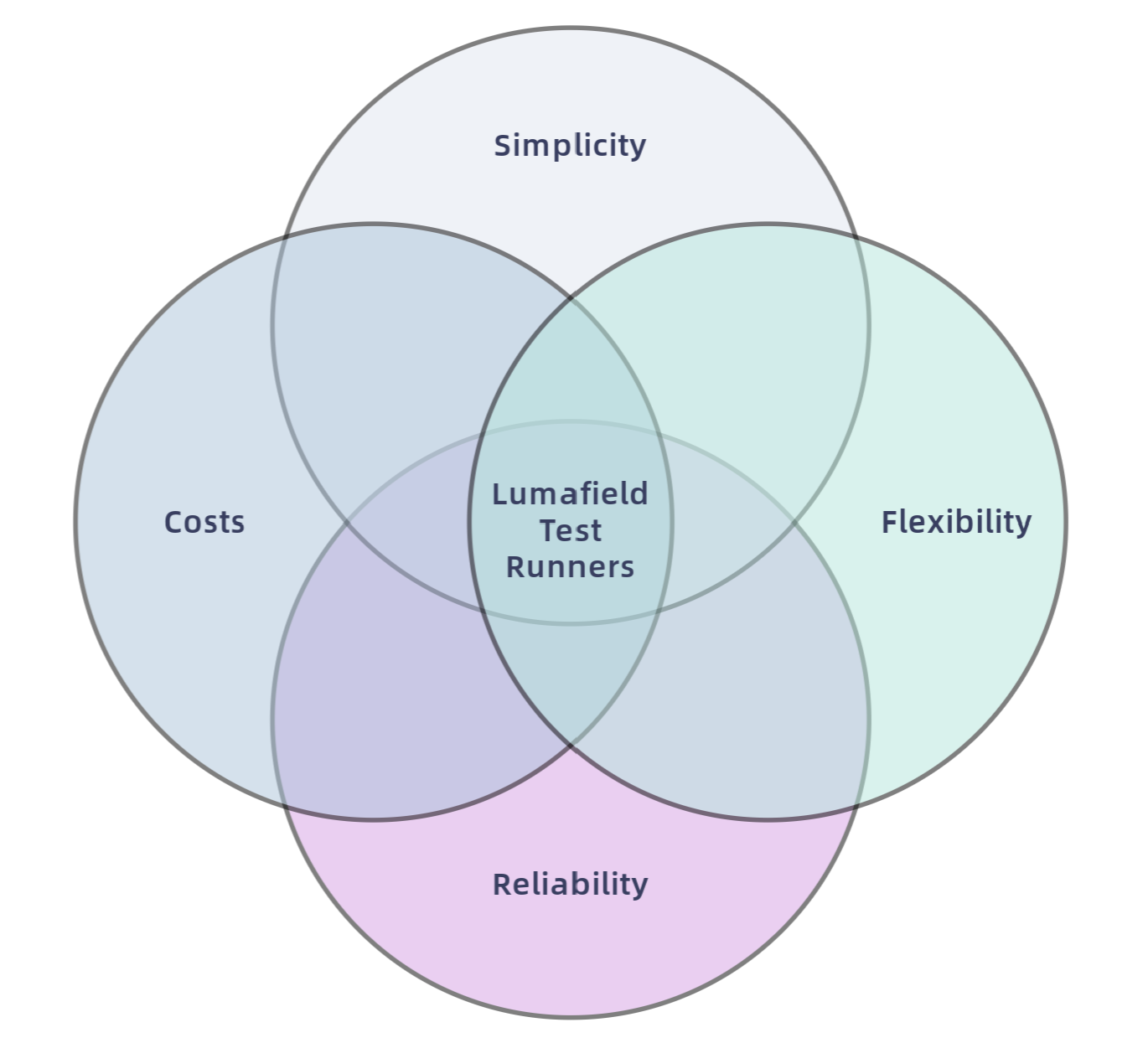
When testing Voyager, our cloud-based in-browser application for visualizing and analyzing CT scan data, the engineers at Lumafield adhere to a few core principles: reliability, cost, flexibility, and simplicity.
- Reliability: Tests must run consistently and accurately. They must not impede the productivity of engineers.
- Costs: Test costs must stay within the limits of a defined budget.
- Flexibility: Tests must be able to be executed on various machine architectures, including those that are GPU-enabled.
- Simplicity: Tests should be easy to design, run, and maintain with minimal setup.
At the dawn of Voyager, we opted to run our Continuous Integration (CI) pipeline on GitHub Actions. GitHub Actions is a powerful tool and since our source code is also hosted on GitHub, the decision made perfect sense.
Additionally, leveraging GitHub-owned "runners" (machines leased from GitHub to run GitHub Actions) made it easy to set up our CI pipeline with minimal issues. However, as time passed, we began to encounter several drawbacks:
- High costs: Machine costs were higher than we would have liked to pay, ballooning to thousands of dollars despite having only a handful of contributing.
- Lack of GPU Support: GitHub does not offer machines with GPUs. This has since changed.
- Architecture Limitations: x86 architecture was only offered. This has since changed.
Given these challenges, we decided to host our own AWS EC2 Spot instances to run GitHub Actions, rather than relying on GitHub-owned runners.
Needed Context: Our CI Pipeline
With each push to a branch in our codebase, we kick off a CI pipeline composed of a series of GitHub Actions:
- Building services/apps: Our apps are built with docker buildx (using Dockerfiles as blueprints). The image is then pushed up to AWS Elastic Container Registry (ECR).
- Running tests: The apps built in the last step are then tested. We have various tests – including frontend/backend unit tests, integration tests, style checks, and security checks.
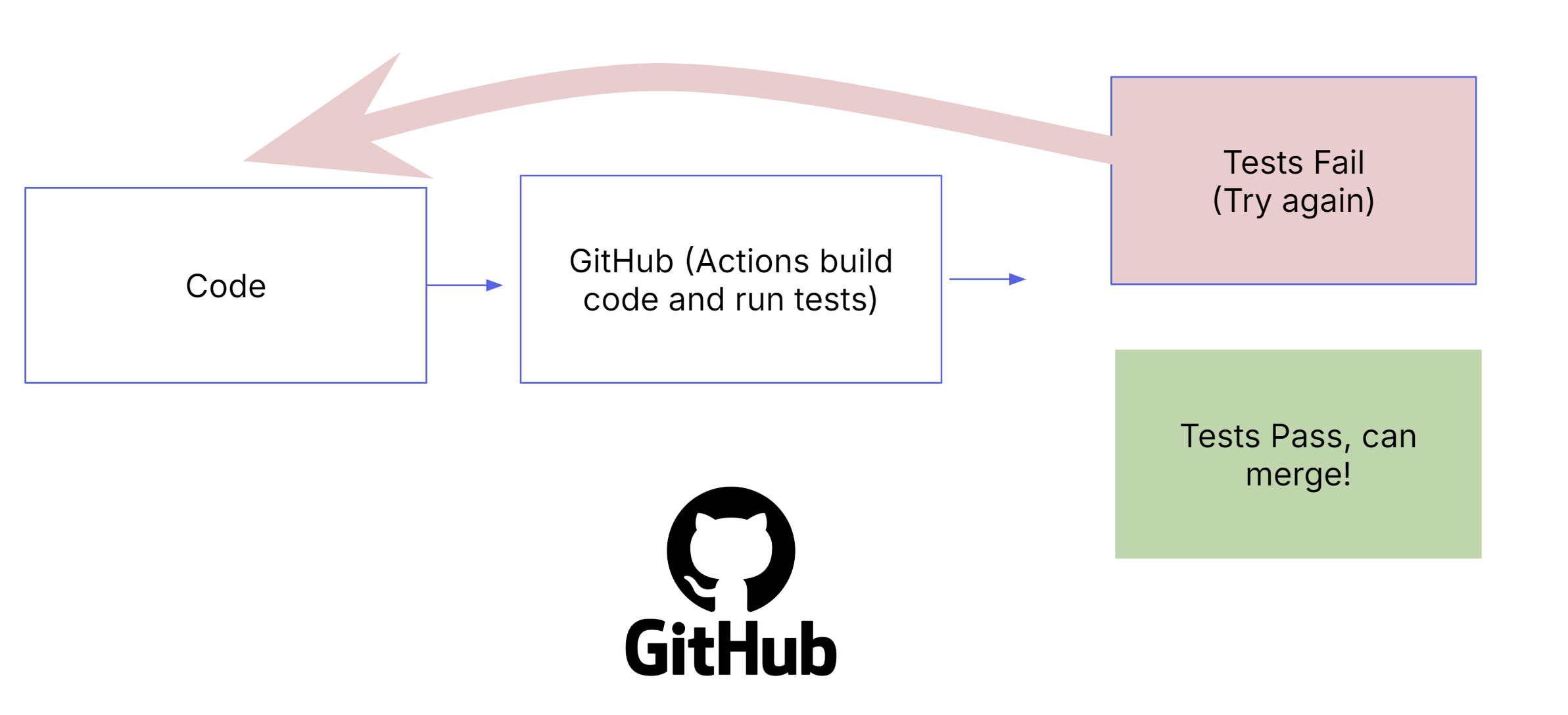
It's important to call-out that all tests must pass in order to be able to merge into the codebase. If a test fails, the engineer must determine the point of failure and fix the underlying issue (or, in cases where it's a "flaky" test, rerun the GitHub Action).
Switching Over To Self Hosted AWS Spot EC2 Instances
Amazon Web Services (AWS) Spot EC2 Instances provide a cost-effective solution for running GitHub Actions. With Spot Instances, AWS enables bidding on unused EC2 capacity at a substantially lower cost—sometimes up to 90% less. This makes them an excellent choice for flexible, interruption-tolerant workloads such as CI/CD pipelines.
With this motivation in mind, we moved forward. It took two attempts to land on a solution that aligned with the core principles outlined in the beginning of this post.
Solution Attempt 1: Self Hosted Runners on Kubernetes (AWS EKS)
Fortunately, GitHub Actions maintains a solution for teams that would like to self-host their own runners via a Kubernetes controller.
The deployment for actions-runner-controller was as followed:
- Use Terraform to configure an EKS Cluster, with autoscaling node groups.
- Within EKS, deploy the
actions-runner-controllerHelm charts along with any additional necessary Kubernetes manifests. - Deploy
autoscalerto handle scaling up/down AWS Spot Instances (nodes). We scaled from zero to capture as much cost savings as possible.
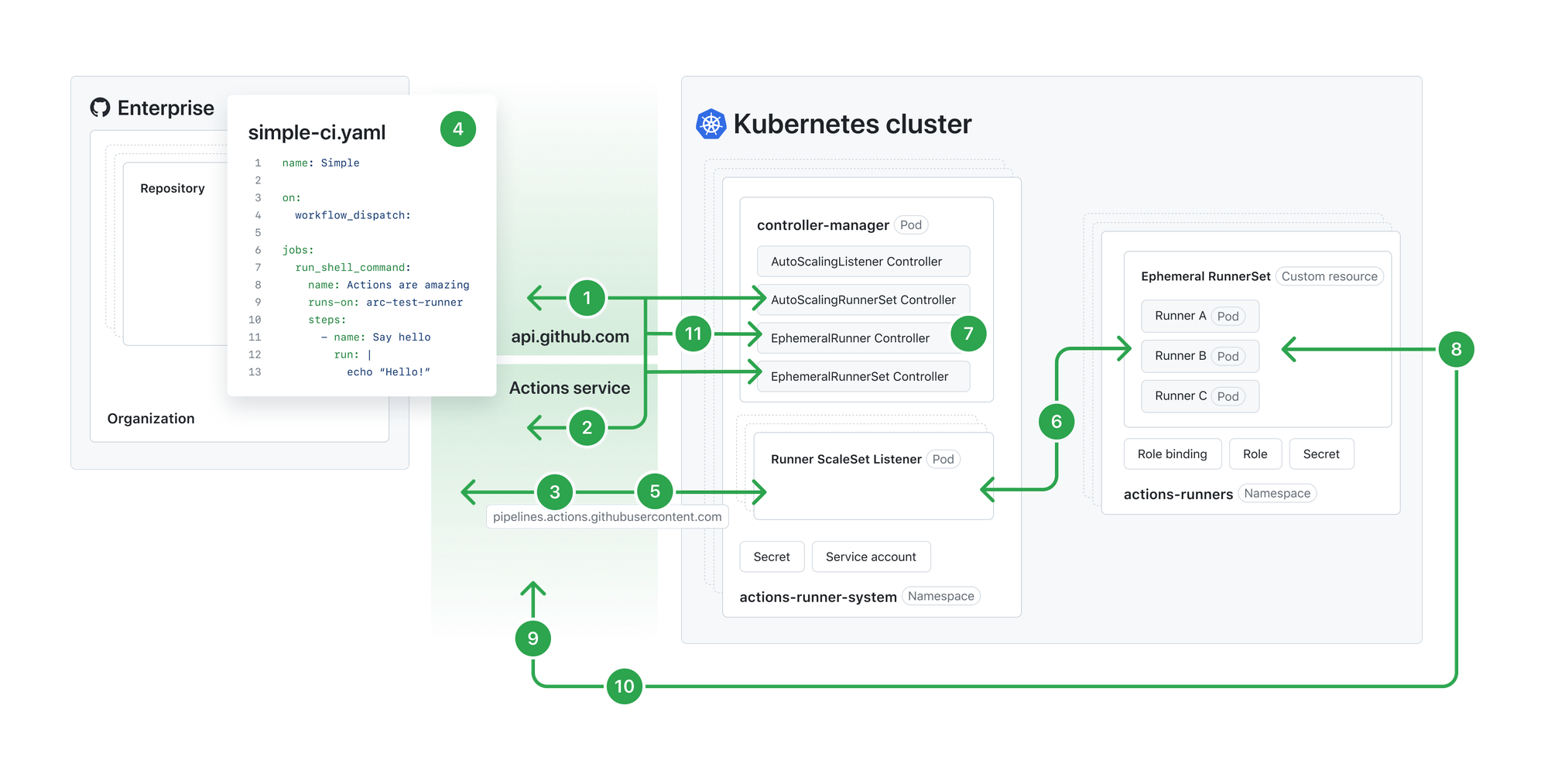
In terms of running tests – a RunnerSet Pod is created via a deployed GitHub-listening "operator service" (controller-manager) Pod as soon as a GitHub Action task is queued.
This new RunnerSet Pod enters a Pending state until EKS makes a Spot instance available for use as a Kubernetes Node. Once the test runs to completion, the pod is Terminated. After a certain time, the Spot instance is drained and removed from our EKS Node list.
On paper, this should have worked well ...so what went wrong?
What Went Wrong: Kubernetes
There were quite a bit of annoyances with running GitHub Actions on AWS Spot instances in Kubernetes, that it was ultimately decided that this solution was not viable.
Problem 1: Unclear Kubernetes SIGTERM Signals
When Kubernetes needs to terminate a Pod, it sends a SIGTERM signal to the container, prompting a graceful shutdown.
However, during test execution, Kubernetes would occasionally send a SIGTERM signal (unrelated to Spot Instance early termination) before the test completed.
The result? Incomplete tests and generic errors ("operation cancelled") reported in the GitHub Actions UI, with little useful information in the logs. This led to frustrated engineers spending hours debugging with no clear resolution. These issues felt like an early red flag.
Problem 2: Controller Always On
To enable communication between GitHub and our EKS cluster, a controller-manager service must run continuously to listen for incoming requests from GitHub. This requirement forces us to keep at least one machine running at all times to maintain these services—directly contradicting our goal of minimizing costs.
Problem 3: General Kubernetes Maintenance
Kubernetes is powerful but demands ongoing maintenance—handling updates, monitoring clusters, and fixing security issues. Each component, from the control plane to worker nodes, requires regular patching, which adds overhead. As Kubernetes evolves, breaking changes and version deprecations can force migrations. AWS EKS only supports certain Kubernetes versions for limited periods, adding to the workload.
Solution Attempt 1 (Kubernetes): Summary - Not Good!
Here are the final results of this method:
| Principle | Status |
|---|---|
| Reliability | ❌ |
| Cost | ❌ |
| Flexibility | ✅ |
| Simplicity | ❌ |
In summary, this solution was not good. Although, we did gain flexibility via being able to launch any EC2 instance offered by AWS at any moment (ARM, x86, GPU-enabled, etc.).
However, with rising costs from unsuccessful fixes and engineers spending more time debugging than developing, it became clear this wasn’t sustainable.
We ditched Kubernetes and shifted to the power of AWS Lambda, AWS Simple Queue Service (SQS), and AWS EventBridge.
Solution Attempt 2: Scaling via AWS Lambdas
I'd like to start this section with a wise proverb:
"All one needs is an EC2 instance to run a GitHub Action. So why all the extra nonsense?"
By embracing this simplification, we should be able to eliminate Kubernetes entirely and spin up a Spot EC2 instance only when necessary.
Fortunately, we can leverage Philip's Labs' open source Terraform module, 'Self-Hosted Scalable GitHub Actions runners on AWS' to do just that. Let's dive into their provided diagram below.
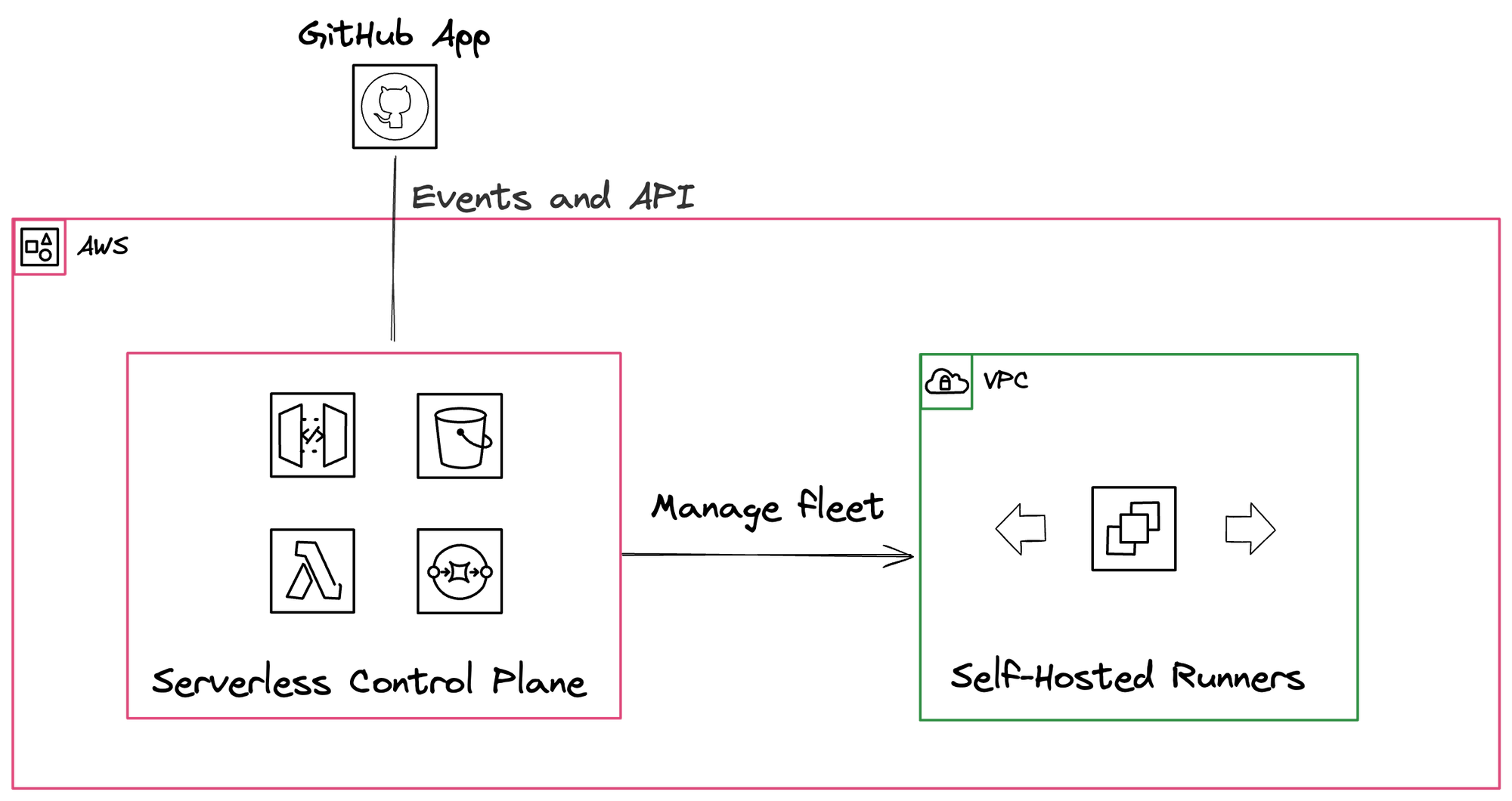
After deploying out the terraform module (to do so, check out the docs), we get quite a bit of new serverless infrastructure that work together to run GitHub Actions. Let's walkthrough it step-by-step.
GitHub App and Webhook
First and foremost, we need to create and install a "GitHub App" who's sole job will be to listen for changes in our Actions queue. When there is an event, it will hit a /webhook endpoint which is being served on AWS's API Gateway.
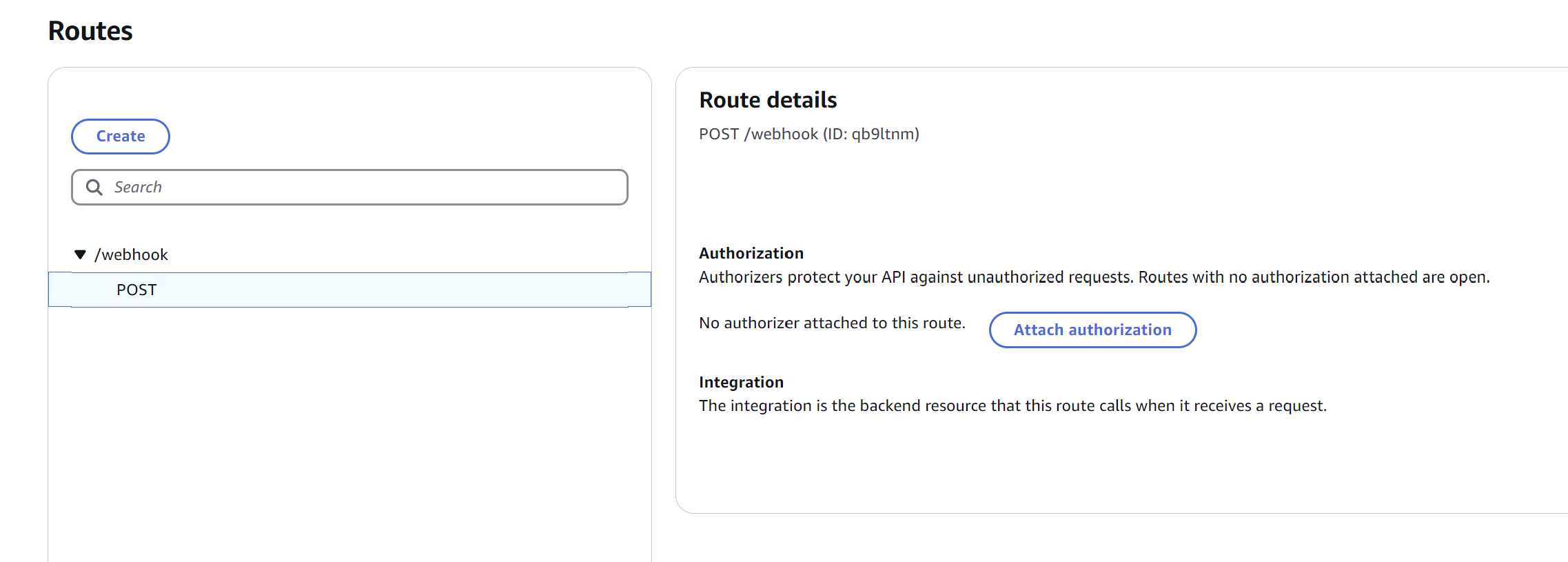
When our GitHub App hits the /webhook endpoint with GitHub Action data, we see that it is forwarded to an AWS Lambda function (ours is called masu-gh-ci-webhook.)
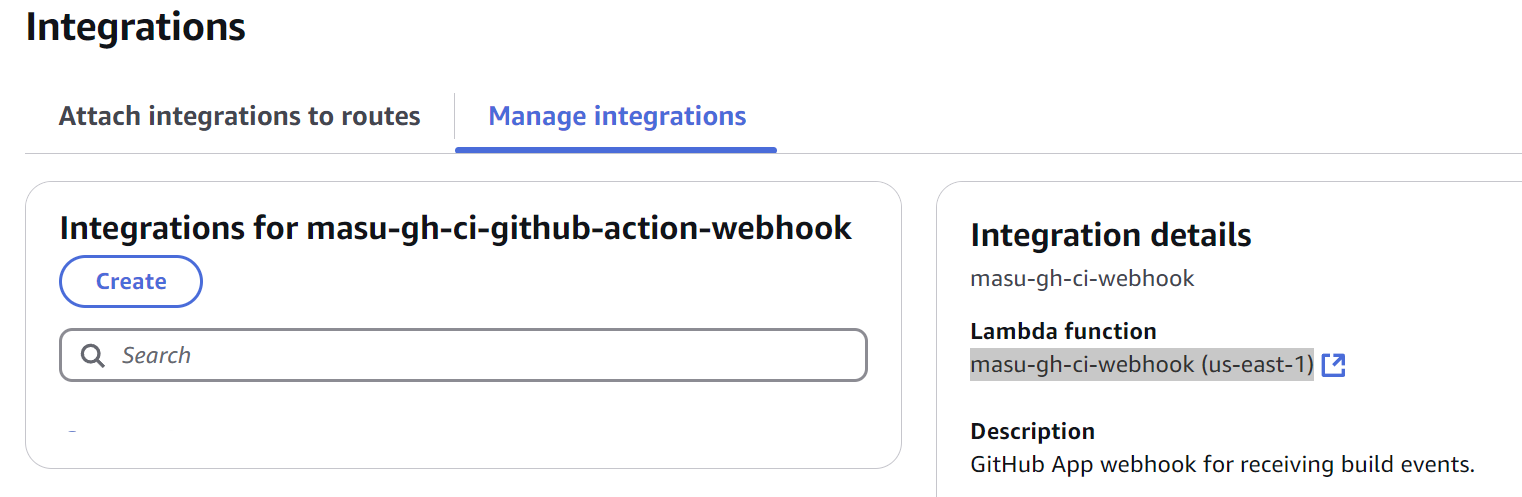
The deployed webhook's Lambda function's primary role is to capture GitHub Action events and push them to an AWS Simple Queue Service (SQS) queue (see: handleWorkflowJob function).
Scaling Up
The AWS SQS queue is configured with an additional Lambda trigger, ensuring events are processed automatically.
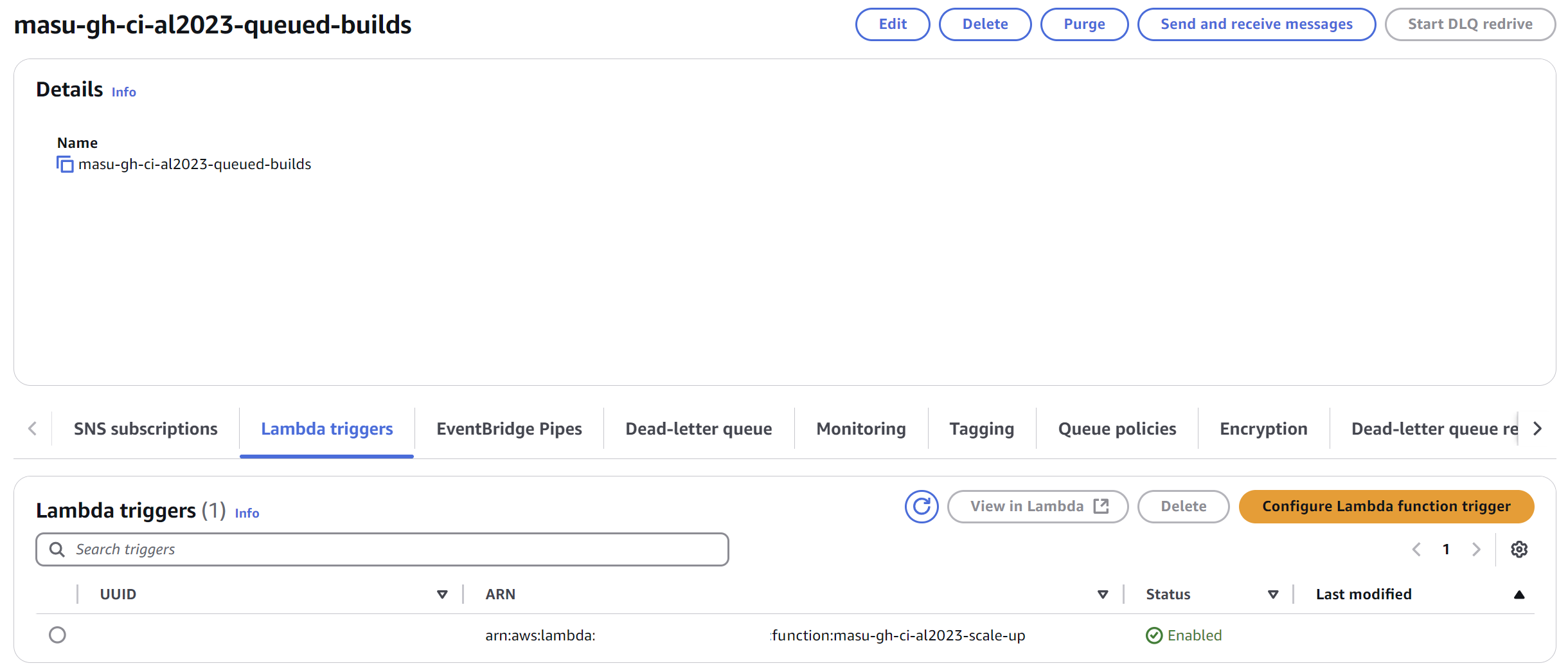
This SQS Lambda trigger calls a scaleUp function that is responsible for creating new EC2 instances (through calling a createRunner function).
Upon launch, the EC2 instance will be registered to GitHub, and thus GitHub will be able to use the EC2 instance to run the GitHub Action. We can now run tests!
Scaling Down
No surprises here – we also deploy out another AWS Lambda to handle this. However, this Lambda is invoked every 5 minutes via an Amazon EventBridge Scheduler rule seen below.
The deployed scale-down Lambda has a function called evaluateAndRemoveRunners where all the idle GitHub Runners are queried from GitHub itself, and matched with the corresponding deployed AWS EC2 instance. The EC2 instance is then programmatically removed (and thus we stop paying for it)!
Here's a more detailed diagram of everything at work:
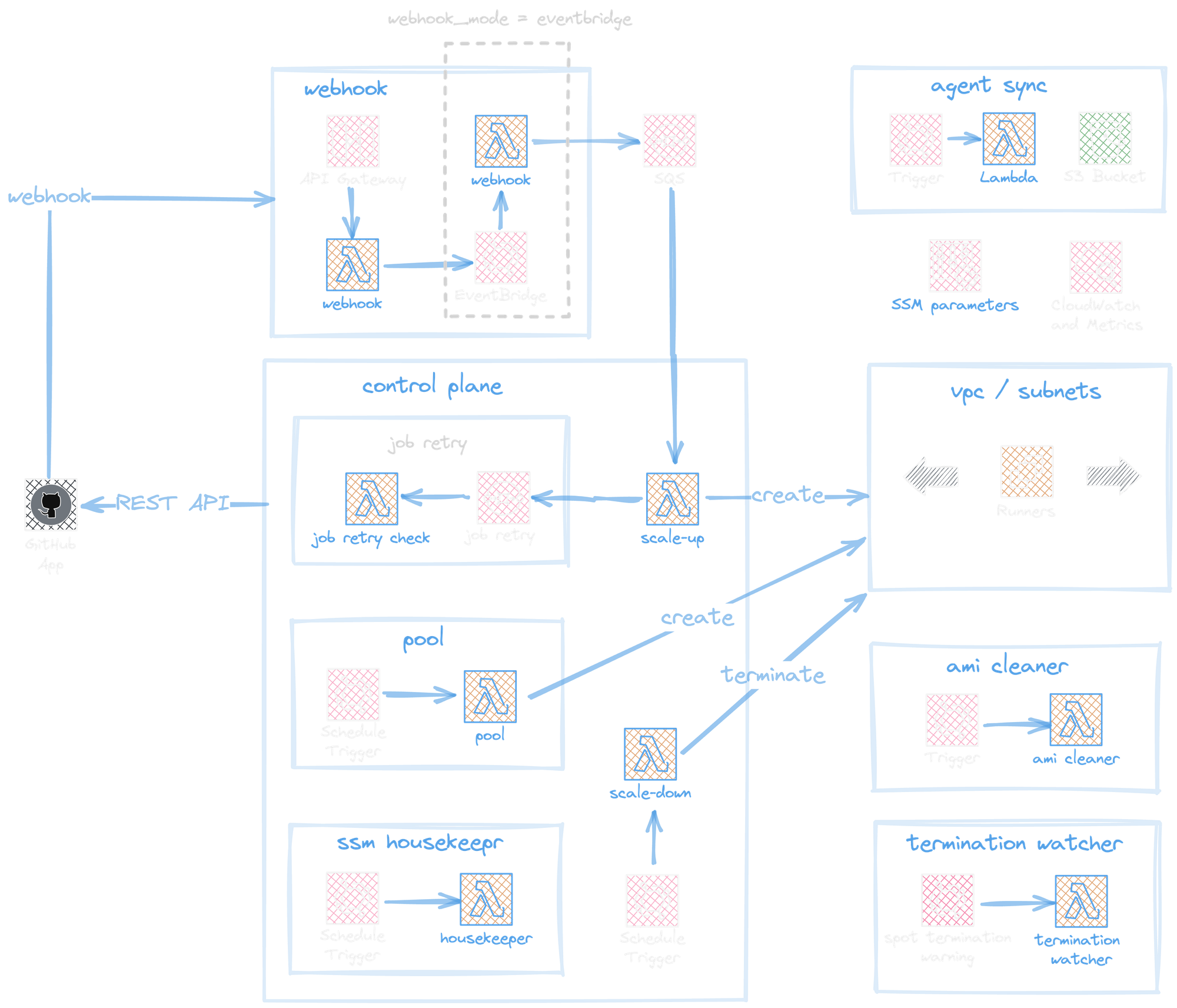
Solution Attempt 2 (Lambdas): Summary - Good!
Drumroll please...
| Principle | Status |
|---|---|
| Reliability | ✅ |
| Cost | ✅ |
| Flexibility | ✅ |
| Simplicity | ✅ |
Finally, our test cluster is running as we had hoped it would. The cluster has been completely stable (only with very rare AWS Spot Early Termination ending tests early – which is expected). Monthly costs have been slashed by 75%. And there is virtually no maintenance required aside from a mandatory GitHub runner software upgrade every 2 months or-so.
Improvements
Now the good part, we can take something already good and make it great. With some simple tweaks, we were able to speed up our tests, all while making things even cheaper.
Reduce EBS Bottleneck
Each of our tests require to pull, extract and launch Docker images stored in AWS's Elastic Container Registry (ECR). This is a slow process bottlenecked by AWS's EBS volumes (the storage volumes attached to the EC2 instances).
By raising the maximum IOPS configuration for each EBS volume (up to 16,000 IOPS), we experienced a significant speed boost.
Cost-wise, it's advisable to conduct a cost analysis using AWS's Cost Estimation tool. Despite the increased expenses (albeit rather small), we found the performance gains justified the cost.
Remove AWS NAT Gateway
NAT Gateway charges are often a significant pain point for DevOps engineers. Initially, we discovered that half of our test costs stemmed from NAT Gateway usage.
This made sense, as each run involved pulling data from GitHub (e.g., git checkout, git lfs pull) and external sources like package repositories. Since our EC2 instances are deployed in private subnets, internet-bound traffic must pass through a NAT Gateway.
To mitigate this, we took a chance on fck-nat, a Terraform module that deploys a custom NAT Gateway on an EC2 instance of your choice (which, is much cheaper than paying per-use of a typical AWS NAT Gateway). The decision paid off—deployment was smooth, performance has been flawless, and we've significantly reduced costs.